ubuntu 配置hadoop伪分布式
本文最后更新于:2022年5月5日 晚上
这里选择安装伪分布式的形式原文链接
1 安装前准备
下载hadoop和jdk安装包,因为伪分布式版本要求,我们选择hadoop2.7.3 与java 1.8

2 安装 ssh server
1 | |
1 | |
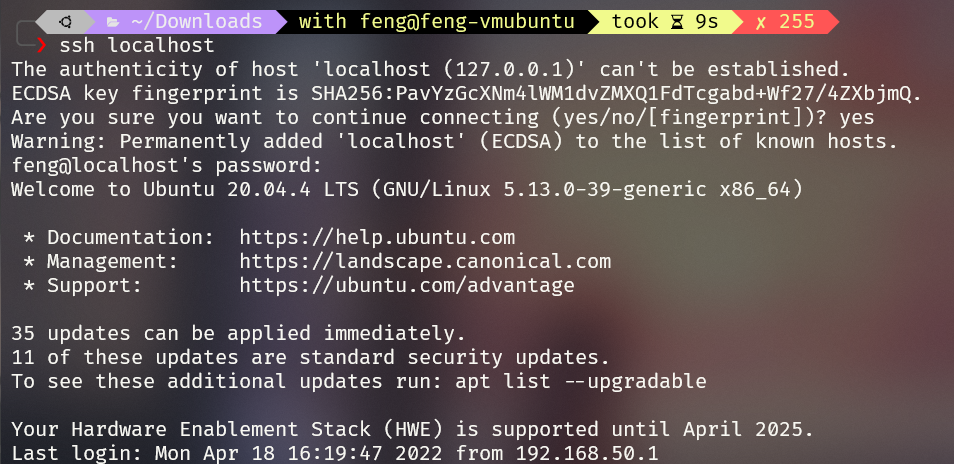
1 | |

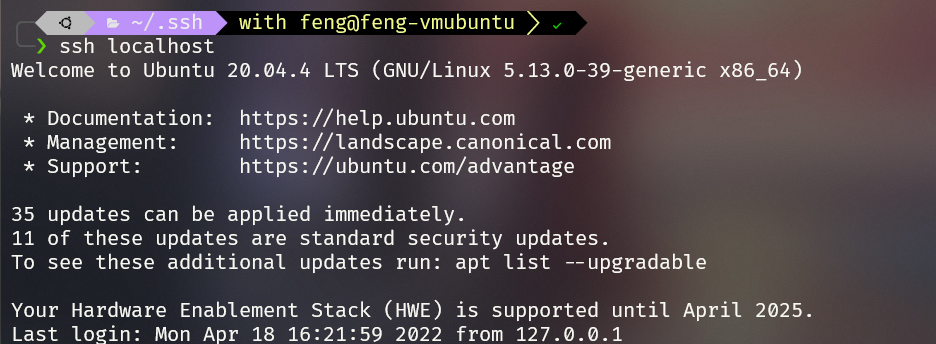
3 生成密钥对
1 | |
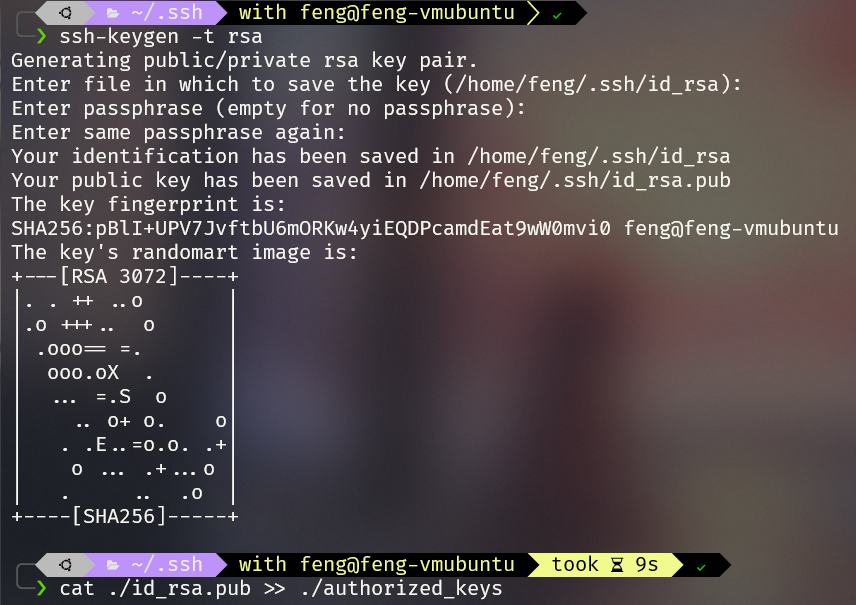
1 | |
4 安装jdk
创建文件夹
1
sudo mkdir -p /usr/lib/jvm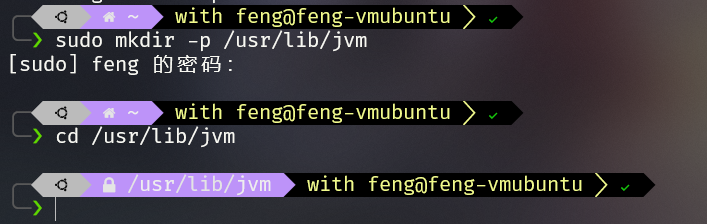
解压jdk到/usr/lib/jvm
1
sudo tar zxvf jdk-8u101-linux-x64.tar.gz -C /usr/lib/jvm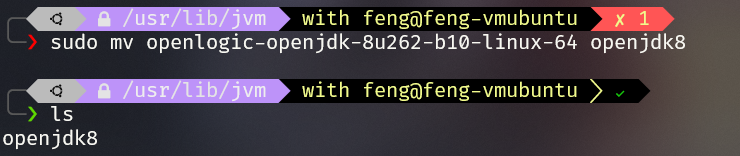
配置环境变量
1
sudo vim /etc/profile1
2
3
4
5#set java environment
export JAVA_HOME=/usr/lib/jvm/openjdk8
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:{JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
查看安装版本
1
2
3
4## 使环境变量生效
source /etc/profile
## 查看java版本
java -verison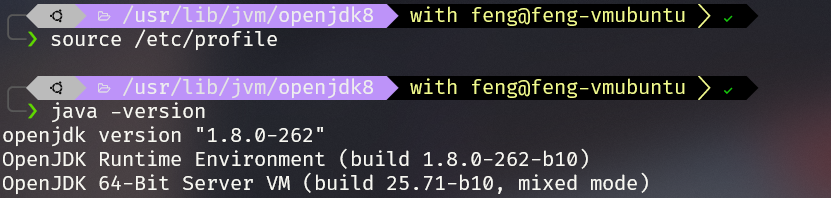
5 配置hadoop
5.1 解压重命名
1 | |

5.2 配置环境变量
1 | |
1 | |

1 | |
5.3 更改配置文件
修改权限
1
2## feng 是我的用户名
sudo chown -R feng /usr/local/hadoop/
修改JAVA_HOME
可以直接使用vscode 远程连接虚拟机,对vim命令不太熟悉的我们更方便
1
2cd /usr/local/hadoop/etc/hadoop/
vim hadoop-env.sh
core-site.xml
添加内容
1
2
3
4
5
6
7
8<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>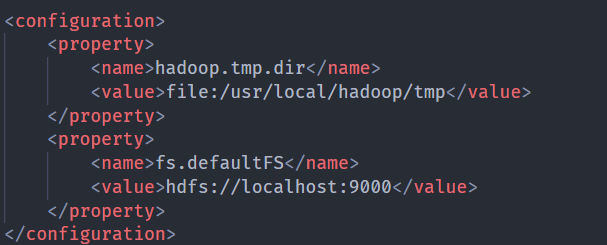
hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
12<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>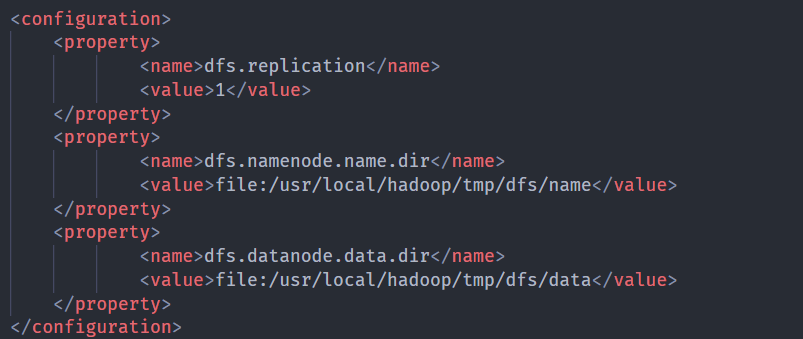
mapred-site.xml
1
mv mapred-site.xml.template mapred-site.xml1
2
3
4<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>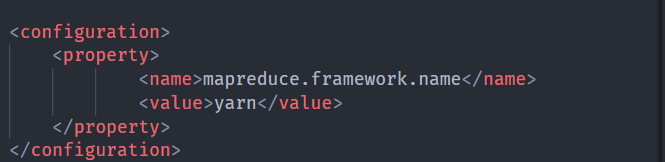
yarn-site.xml
1
2
3
4<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>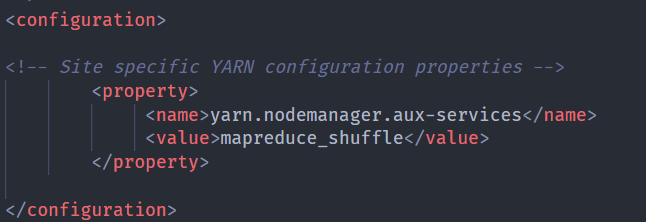
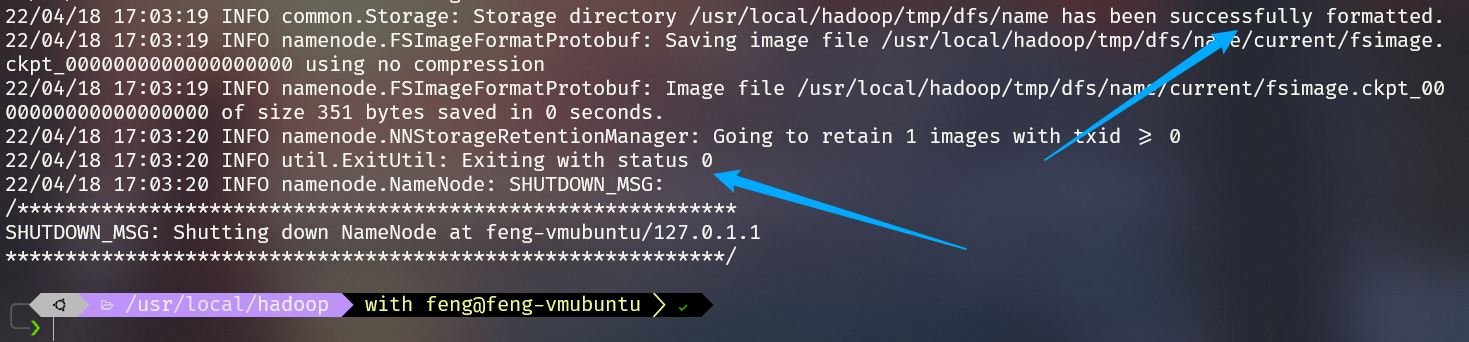
6 格式化
1 | |
成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错
7 启动
1 | |
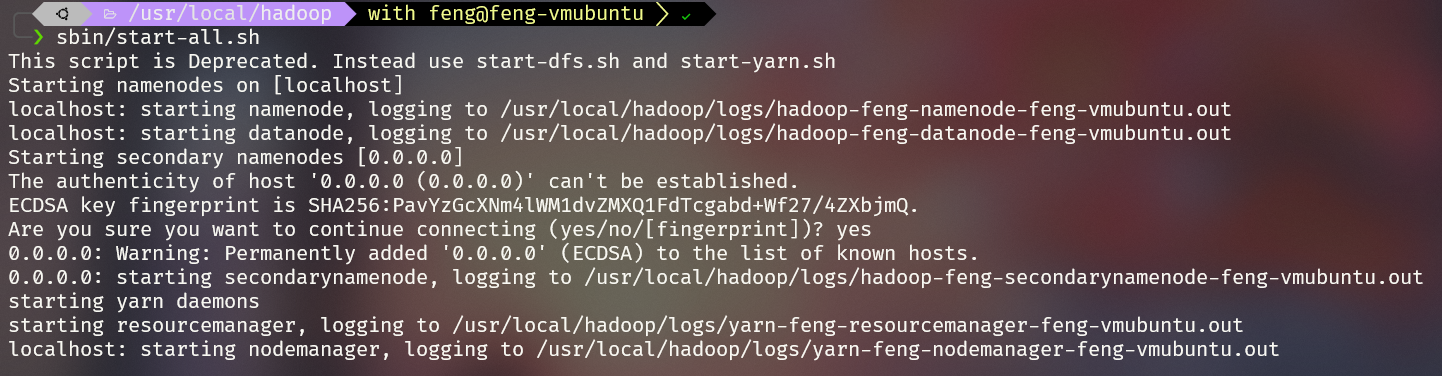
8 查看jps
1 | |
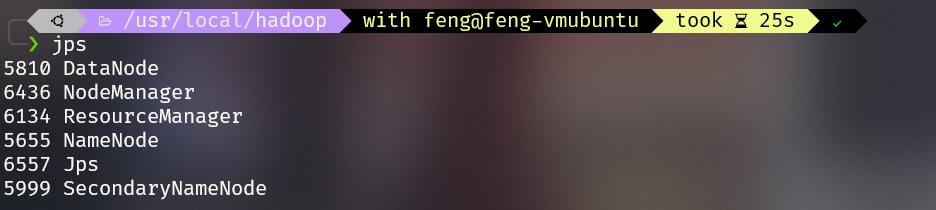
出现这个说明hadoop安装成功
9 上传文件
创建用户文件夹
1
2./bin/hdfs dfs -mkdir /user
./bin/hdfs dfs -mkdir /user/feng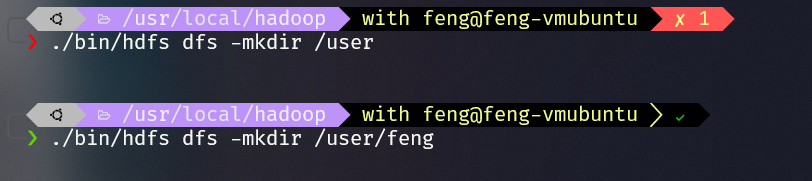
本地新建一个文件
1
vim hadooptest1.txt
上传文件
1
./bin/hdfs dfs -put hadooptest1.txt查看
1
./bin/hdfs dfs -ls
1
./bin/hdfs dfs -cat hadooptest1.txt
总结
hadoop在一年前配置过环境,hadoop,hdfs,hbase,mapeduce,断断续续搞了一个月。
如今重新配置,也还是配置了一个多小时。
hadoop作为一个分布式系统基础架构,hdfs提供了安全可靠的分布式文件存储系统,mapreduce更是一个高效的超大规模数据处理方法。
可惜因为效率等种种原因,hadoop逐渐被淘汰了,不过其推广的mapreduce思想永不过时。