boolifprime(int n) { if (n == 2 || n == 3) return1; if (n % 6 != 1 && n % 6 != 5) return0; for (int k = 5; k <= floor(sqrt(n)); k += 6) if (n % k == 0 || n % (k + 2) == 0) return0; return1; }
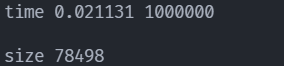
串行 此时运行时间为
time=0.156363
202203171659060
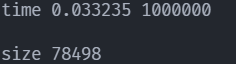
并行 此时运行时间为
time=0.015401
202203171713716
2. 使用筛法
我们可以标记所有合数,然后求质数
1 2 3 4 5 6 7 8 9 10 11
long sign[SIZE + 1];
voidgetPrime(vector<long> &prime) { int N = sqrt(SIZE); for (int i = 2; i <= N; i++) { if (!sign[i]) for (int j = i; j <= SIZE / i; j++) sign[i * j] = true; }
int N = sqrt(SIZE); // 并行的使用筛法找出所有合数 #pragma omp parallel for num_threads(NUM_THREADS) for (int i = 2; i <= N; i++) { if (!sign[i]) for (int j = i; j <= SIZE / i; j++) sign[i * j] = true; }
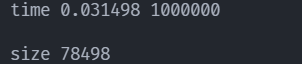
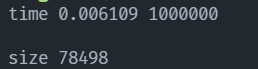
此时运行时间为
time=0.012204
202203171716363
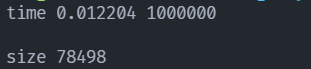
在寻找合数时并行
1 2 3 4 5 6 7 8 9
int N = sqrt(SIZE); // 并行的使用筛法找出所有合数 for (int i = 2; i <= N; i++) { if (!sign[i]) #pragma omp parallel for num_threads(NUM_THREADS) for (int j = i; j <= SIZE / i; j++) sign[i * j] = true; }